
Bajo la mentoría del Profesor Nacho Molina, nosotros—Daveed Vodonenko, Darius Vulturu y Lucas Portela—desarrollamos MLHD (Machine Learning for Human Detection) porque nos fascina genuinamente ese momento en el que las matemáticas elegantes se transforman en algo que funciona en el mundo real. Para nosotros, el machine learning no es magia, sino matemáticas aplicadas en acción: la optimización dando forma a millones de parámetros, la probabilidad guiando decisiones bajo incertidumbre y la intuición geométrica convirtiendo píxeles en bruto en estructuras con significado, como la localización de personas en una imagen.MLHD es nuestro intento de cerrar la brecha entre teoría y práctica en un entorno donde realmente importa: las cámaras de seguridad en fábricas, donde la iluminación irregular, el desenfoque y el desorden visual ponen constantemente a prueba a los modelos estándar. Al diseñar un detector ligero al estilo YOLO, adaptado específicamente a grabaciones industriales, nuestro objetivo no fue solo crear un modelo que funcione bien en el papel, sino una base fiable para sistemas enfocados en la seguridad, como la monitorización de zonas y las alertas de proximidad.
¿En qué consistía vuestro proyecto?
¿En qué consistía vuestro proyecto?
Nuestro proyecto tenía como objetivo desarrollar un algoritmo de aprendizaje automático capaz de detectar personas de forma precisa y eficiente a partir de cámaras CCTV ubicadas en un entorno industrial.
¿Qué impacto o problema real queríais abordar?
¿Qué impacto o problema real queríais abordar?
A pesar de los avances tecnológicos, los accidentes y fallecimientos en fábricas siguen siendo una preocupación persistente en muchas industrias a nivel mundial. El objetivo de este proyecto era desarrollar un módulo ligero y listo para usar que pudiera servir como base para futuros sistemas de seguridad, como el análisis de proximidad entre personas y maquinaria, la detección de entrada en zonas peligrosas y la identificación de situaciones de riesgo inminente. Todas estas aplicaciones dependen de determinar con precisión la ubicación de los trabajadores en cada fotograma.
Además, muchas fábricas necesitan información operativa, como la ubicación de los trabajadores en la planta y el tiempo que pasan en descansos; datos que nuestro modelo está diseñado para proporcionar. Otro objetivo clave era que el sistema fuera verdaderamente ligero y fácil de implementar: requiere un ajuste mínimo y puede ejecutarse en hardware relativamente antiguo, algo común en muchos entornos industriales.
¿Qué enfoques técnicos y herramientas utilizasteis, y por qué los elegisteis?
¿Qué enfoques técnicos y herramientas utilizasteis, y por qué los elegisteis?
La mayor parte del proyecto se implementó en Python. Utilizamos PyTorch para desarrollar y entrenar los componentes principales del modelo, incluyendo el backbone (que analiza cada fotograma y extrae características visuales) y la detection head (que predice dónde se encuentran las personas en la escena), así como para realizar operaciones matriciales eficientes y gestionar el flujo general del entrenamiento.
Para mejorar la diversidad del conjunto de datos y la robustez del modelo, aplicamos técnicas de aumento de datos con Albumentations y OpenCV. Matplotlib se utilizó para visualizaciones básicas, gráficos de rendimiento y análisis del entrenamiento.
Por favor, cuéntennos sobre su proyecto:
Por favor, cuéntennos sobre su proyecto:
Metodología
Versión 1 (menos técnica)
Construimos un sistema que toma vídeo de cámaras CCTV y detecta automáticamente a las personas en las imágenes. Primero, extraemos fotogramas individuales de los vídeos y los estandarizamos para que todos tengan el mismo formato y tamaño. Para que el sistema funcione mejor en condiciones reales (zonas oscuras, reflejos, desenfoque o baja calidad de imagen), generamos versiones adicionales de las mismas imágenes realizando pequeños ajustes, como modificar el brillo, añadir ruido o simular desenfoque por movimiento.
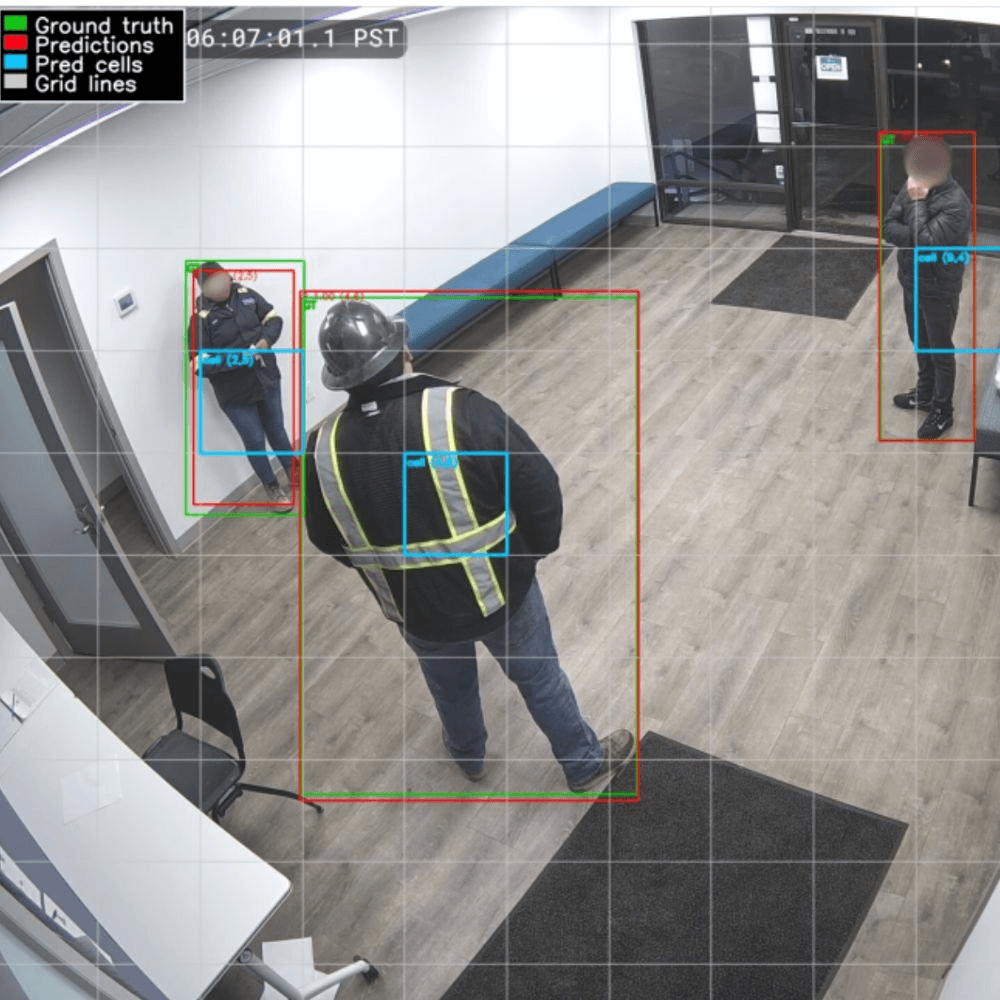
Después, etiquetamos las imágenes de entrenamiento dibujando recuadros ajustados alrededor de cada persona, para que el modelo aprenda cómo es una persona y dónde aparece en el fotograma.
El modelo tiene dos partes: una que analiza la imagen y aprende patrones visuales útiles (Backbone), y otra que decide, en diferentes regiones de la imagen, si hay una persona y dónde debe colocarse el recuadro (Detection Head). Durante el entrenamiento, el modelo compara repetidamente sus predicciones con las respuestas correctas y se ajusta para cometer menos errores (función de pérdida).
También mejoramos el método de entrenamiento para que el modelo colocara los recuadros con mayor precisión. Finalmente, probamos diferentes configuraciones de entrenamiento para encontrar la más adecuada, entrenamos la mejor versión durante más tiempo y aplicamos técnicas para evitar el sobreajuste. Evaluamos el rendimiento utilizando métricas estándar de detección.
Versión 2 (más técnica)
Nuestro método transforma vídeo CCTV en resultados fiables de “persona detectada” mediante un pipeline estructurado. Extraemos fotogramas, los estandarizamos (conversión de formato, redimensionado y normalización) y aplicamos aumento de datos para manejar variaciones reales como cambios de iluminación, desenfoque o ruido.
Cada persona se etiqueta con un bounding box ajustado, y estas etiquetas se convierten en un formato basado en cuadrícula para que el modelo aprenda no solo si hay una persona en cada celda, sino también su posición y tamaño.
El modelo consta de un backbone convolucional que aprende características visuales y una detection head que genera cinco valores por celda: cuatro para describir el recuadro y uno para la probabilidad de presencia. Utilizamos una función de pérdida combinada y mejoramos la precisión adoptando Complete IoU (CIoU).
Ajustamos hiperparámetros mediante un proceso en dos etapas y utilizamos el optimizador AdamW, reducción de learning rate y early stopping para evitar sobreajuste. El rendimiento se midió con precisión, recall, F1, IoU y Average Precision en conjuntos de validación y prueba.
Resultados
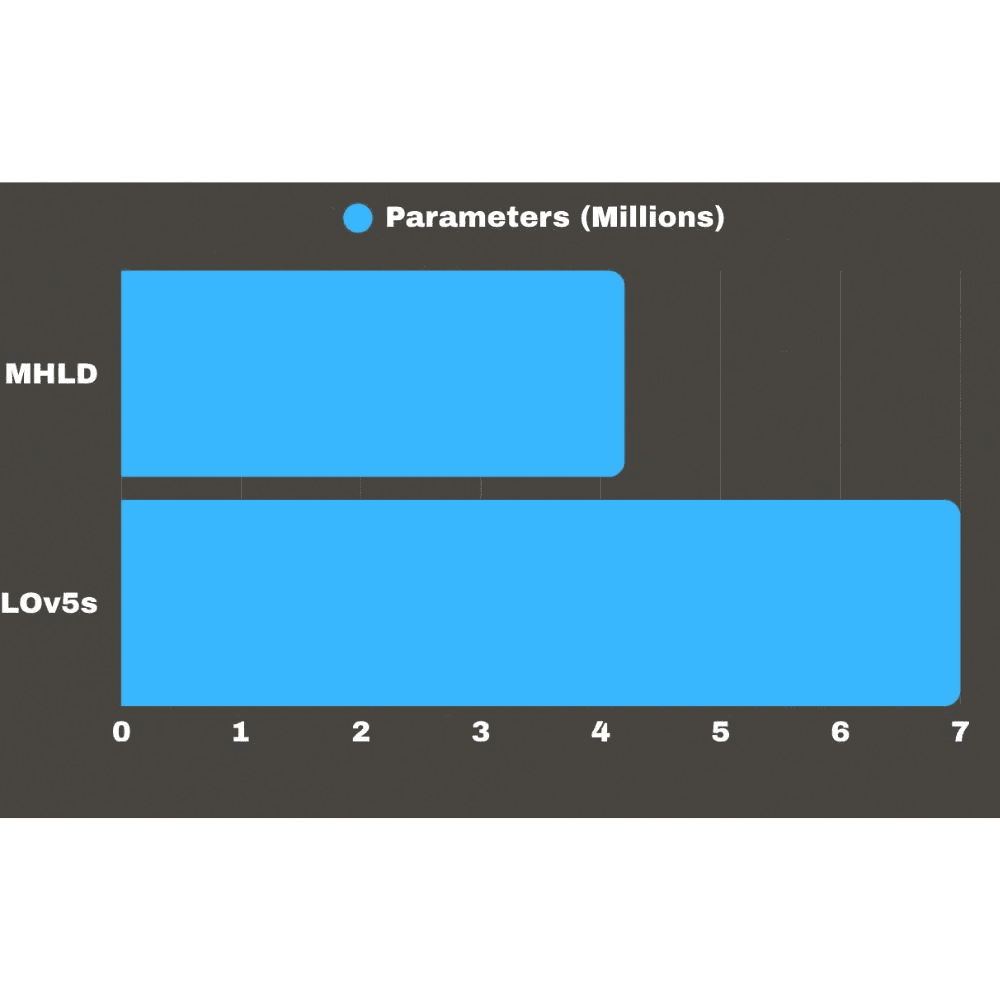
Nuestros resultados muestran que MLHD (nuestro modelo personalizado) supera a YOLOv5s en imágenes reales de CCTV en fábrica. YOLOv5 es un detector general muy utilizado, pero puede rendir peor en entornos específicos si no está adaptado a ellos.
Entrenamos la mejor versión de MLHD con un conjunto de datos altamente variado y aplicamos early stopping. El entrenamiento duró aproximadamente 3 horas y 43 minutos en un Mac M4 Pro.
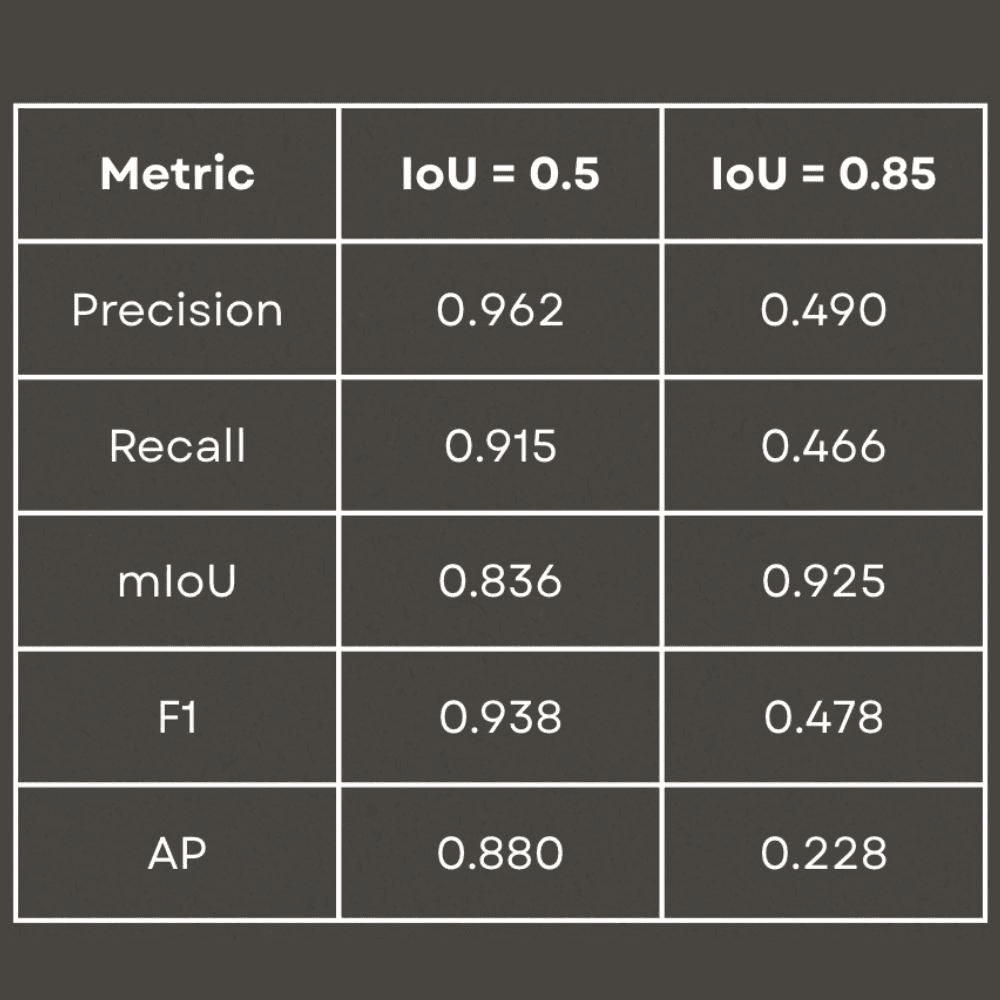
Con IoU = 0.50, MLHD obtuvo: Precisión = 0.965, Recall = 0.916, F1 = 0.940 y AP = 0.884.
Al exigir una alineación extremadamente precisa (IoU = 0.85), el rendimiento disminuyó, algo esperado y generalmente innecesario en aplicaciones reales de vigilancia.
La conclusión principal es clara: un modelo más pequeño y diseñado específicamente para CCTV en fábrica puede superar a un detector general no adaptado.
Conclusiones
Este trabajo demuestra que la detección de personas en CCTV industrial puede ser más fiable cuando el modelo se diseña específicamente para ese entorno. MLHD logra un alto rendimiento con menos parámetros que YOLOv5s.
La bajada de rendimiento con IoU más estrictos refleja una decisión consciente: priorizar la detección fiable de presencia frente a la precisión milimétrica del recuadro. Para aplicaciones de seguridad industrial, esta compensación es aceptable.
MLHD puede servir como primer paso dentro de un sistema de seguridad más amplio, permitiendo alertas de zonas restringidas, monitorización persona-máquina y predicción de incidentes. Su diseño ligero facilita su implementación en entornos reales.
¿Hubo algún reto durante el proceso?
¿Hubo algún reto durante el proceso?
Sí. Inicialmente, el modelo tenía baja precisión. Lo solucionamos ajustando el tamaño de la cuadrícula y mejorando la función de pérdida. También surgieron dificultades relacionadas con el tiempo de entrenamiento, que podía durar días por ejecución. Además, resultó complejo explicar ideas técnicas de forma clara y accesible, lo que requirió múltiples revisiones.
¿Cómo contribuyó el trabajo en equipo?
¿Cómo contribuyó el trabajo en equipo?
El trabajo en equipo fue clave. Tuvimos que reescribir partes del código para que funcionara en distintos sistemas operativos y estandarizar nombres de variables y funciones. La coordinación fue exigente, pero dio como resultado un código más sólido y un informe más coherente.
¿Qué habilidades habéis adquirido o reforzado?
¿Qué habilidades habéis adquirido o reforzado?
Fortalecimos habilidades de trabajo en equipo y comunicación técnica. También adquirimos experiencia práctica en redes neuronales convolucionales, entrenamiento de modelos y ajuste de hiperparámetros. Aprendimos que el machine learning es un proceso iterativo basado en experimentación y análisis riguroso.
¿Planes de futuro?
¿Planes de futuro?
El proyecto puede ampliarse integrando un componente temporal para rastrear personas entre fotogramas consecutivos. También planeamos permitir múltiples detecciones por celda y analizar la imagen a distintos niveles de detalle para mejorar la precisión en escenas concurridas.
From a technical perspective, an important improvement involves addressing the current limitation of one person per grid cell. At the moment, the image is divided into regions where each area can only report a single detection, which can reduce accuracy in crowded scenes. To overcome this, we would adapt the detection approach so that each region can propose multiple possible people and then apply filtering methods to keep the most reliable results. We would also refine the system to analyse the image at different levels of detail, allowing it to better distinguish individuals who are close together. These adjustments would improve robustness and scalability while keeping the overall design of the project consistent.
¿Cómo conecta el proyecto con el Bachelor en Applied Mathematics?
¿Cómo conecta el proyecto con el Bachelor en Applied Mathematics?
El proyecto nos permitió aplicar cálculo, álgebra lineal, probabilidad y estadística en un contexto real. Conceptos teóricos como funciones de pérdida, optimización por gradiente o métricas de evaluación se convirtieron en herramientas prácticas para resolver un problema industrial concreto.
En definitiva, comprendimos que las Matemáticas Aplicadas consisten en diseñar soluciones cuantitativas estructuradas para problemas reales complejos.
Adjuntar imágenes
Adjuntar imágenes

Enlace al proyecto
Enlace al proyecto
Acá .