
Under the mentorship of Prof. Nacho Molina, we—Daveed Vodonenko, Darius Vulturu, and Lucas Portela—built MLHD (Machine Learning for Human Detection) because we’re genuinely fascinated by the moment when elegant mathematics turns into something that works in the real world. For us, machine learning isn’t magic—it’s applied math in motion: optimization shaping millions of parameters, probability guiding decisions under uncertainty, and geometric intuition turning raw pixels into meaningful structure like human locations in a frame. MLHD is our attempt to bridge that theory–practice gap in a setting where it truly matters: factory CCTV, where messy lighting, blur, and clutter constantly challenge standard models. By designing a lightweight YOLO-style detector tailored to industrial footage, we aimed to create not just a model that performs on paper, but a dependable foundation for safety-focused systems like zone monitoring and proximity alerts.
What was your project about
What was your project about
Our project aimed to develop a machine learning algorithm that could accurately and efficiently detect humans from CCTV cameras placed in an industrial environment.
What impact or real-world problem were you aiming to address?
What impact or real-world problem were you aiming to address?
Despite technological advances, factory injuries and fatalities remain a persistent concern across many industries worldwide. The aim of this project was to develop an off-the-shelf, lightweight upstream module that could serve as a foundation for future safety systems, such as human–machine proximity analysis, hazardous-zone entry detection, and near-miss identification. All of these applications rely on accurately determining a worker’s location within each frame.
In addition, many factories require operational insights, such as where workers are positioned on the floor and how long they spend on breaks—information that our model is designed to provide. A further objective was to ensure the system is truly off-the-shelf and lightweight: it requires minimal fine-tuning and can run effectively on relatively outdated hardware, which is still common in many industrial environments.
What technical approaches and tools did you use, and why did you choose them?
What technical approaches and tools did you use, and why did you choose them?
The main bulk of our project was implemented in Python. We used PyTorch to develop and train the core components of the model, including the backbone (which analyzes each frame and extracts visual features) and the detection head (which predicts where people are located in the scene), as well as for efficient matrix operations and overall training workflows. To improve dataset diversity and model robustness, we applied image augmentation using Albumentations and OpenCV, while Matplotlib was used for basic visualizations, performance plots, and training analytics.
Please tell us about your project's:
Please tell us about your project's:
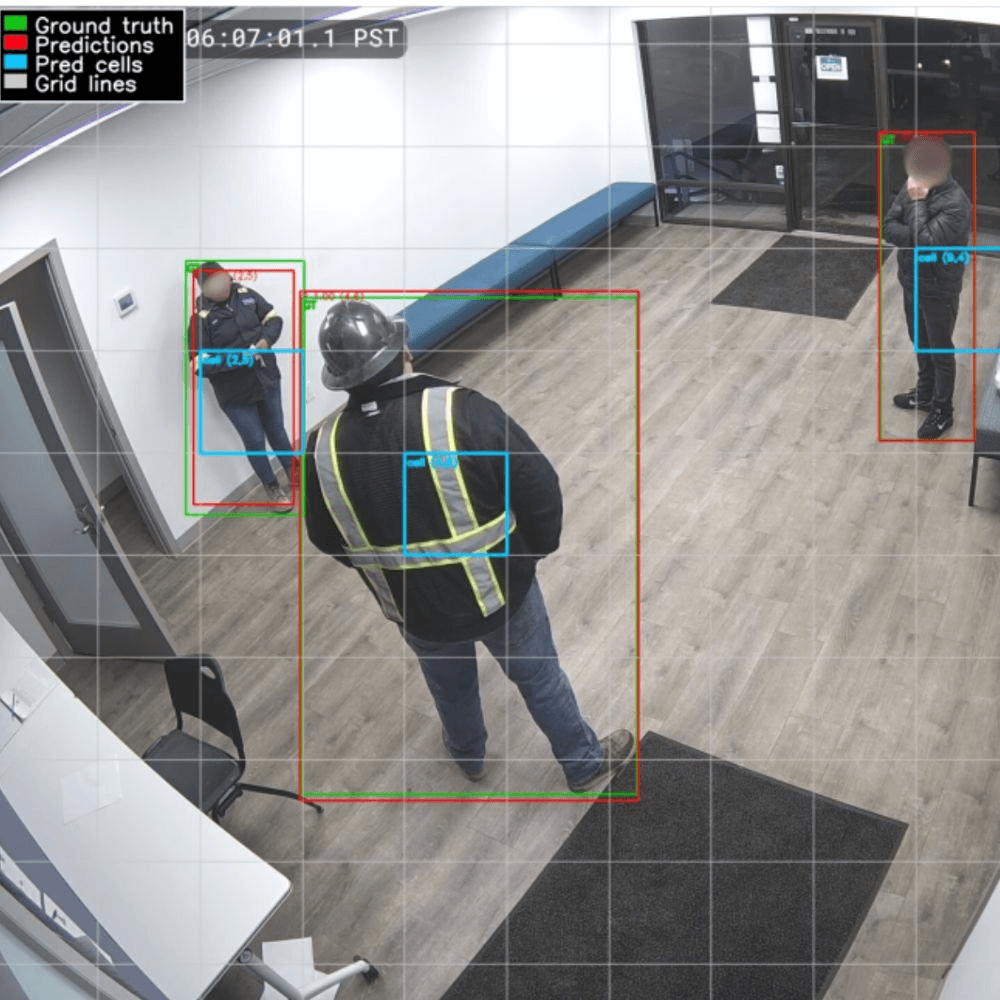
Methodology (we wrote 2 versions of this, one is less technical than the other)
V1) We built a system that takes CCTV video and automatically finds people in the footage. First, we pull out individual frames from the videos and “clean” them so they’re all in the same format and size. To make the system work better in real conditions (like dark areas, glare, blur, or low-quality camera footage), we also create extra versions of the same images by making small changes—like adjusting brightness, adding a bit of noise, or simulating motion blur (dataset augmentation). Then we label the training images by drawing tight boxes around every person, so the model can learn what a person looks like and where they appear in the frame.
The model works like this: one part scans the image and learns useful visual patterns (Backbone), and a second part decides, for different regions of the image, whether a person is there and exactly where the box should go (Detection Head). During training, the model repeatedly compares its guesses to the correct answers and updates itself to make fewer mistakes (Loss function). We also upgraded the training method so the model is better at placing boxes accurately, not just roughly detecting that someone is present.
Finally, we tested many training settings to find what worked best, trained the best version for longer, and used safeguards to avoid “overfitting” (doing well only on training images but poorly on new footage). We judged performance using common detection measures that reflect how often it finds people correctly, how often it misses them, and how well the boxes match the true locations on new, unseen video frames.
V2) Our method turns raw CCTV video into reliable “person detected” results through a structured pipeline. We first extract frames from surveillance videos, standardize them (format conversion, resizing, normalization), and apply data augmentation to help the model handle real-world variation like lighting changes, blur, noise, and compression. Each person in an image is labeled with a tight bounding box, and those labels are converted into a grid-based target format so the model learns not only if a person is present in a grid cell, but also where they are and how big the box should be.
The model has two parts: a convolutional “backbone” that learns visual features from the image (from simple edges to higher-level human shapes), and a “detection head” that outputs five values per grid cell: four numbers describing the bounding box and one probability that a person is present. During training, the model’s predictions are compared to the targets cell-by-cell using a combined loss that teaches both accurate localization and correct detection. We improved bounding-box accuracy by switching from a basic coordinate loss to Complete IoU (CIoU), which better accounts for overlap, alignment, and shape, leading to stronger precision, recall, and average precision.
Finally, we tuned hyperparameters using a two-stage process: a small grid search to shortlist good settings, followed by longer training runs with the best candidates. Training used AdamW optimization, learning-rate reduction when progress stalled, and early stopping to reduce overfitting. Performance was reported with standard detection metrics such as precision, recall, F1, IoU, and Average Precision on held-out validation and test sets.
Results
Our results show that MLHD (our custom model) beats the YOLOv5s baseline on real factory CCTV footage. YOLOv5 is a widely used, fast, general-purpose object detector that finds objects (like people) by drawing bounding boxes around them in an image. It often works well “out of the box,” but it can underperform in a specific environment—like factory cameras—if it isn’t trained or fine-tuned on that kind of footage.
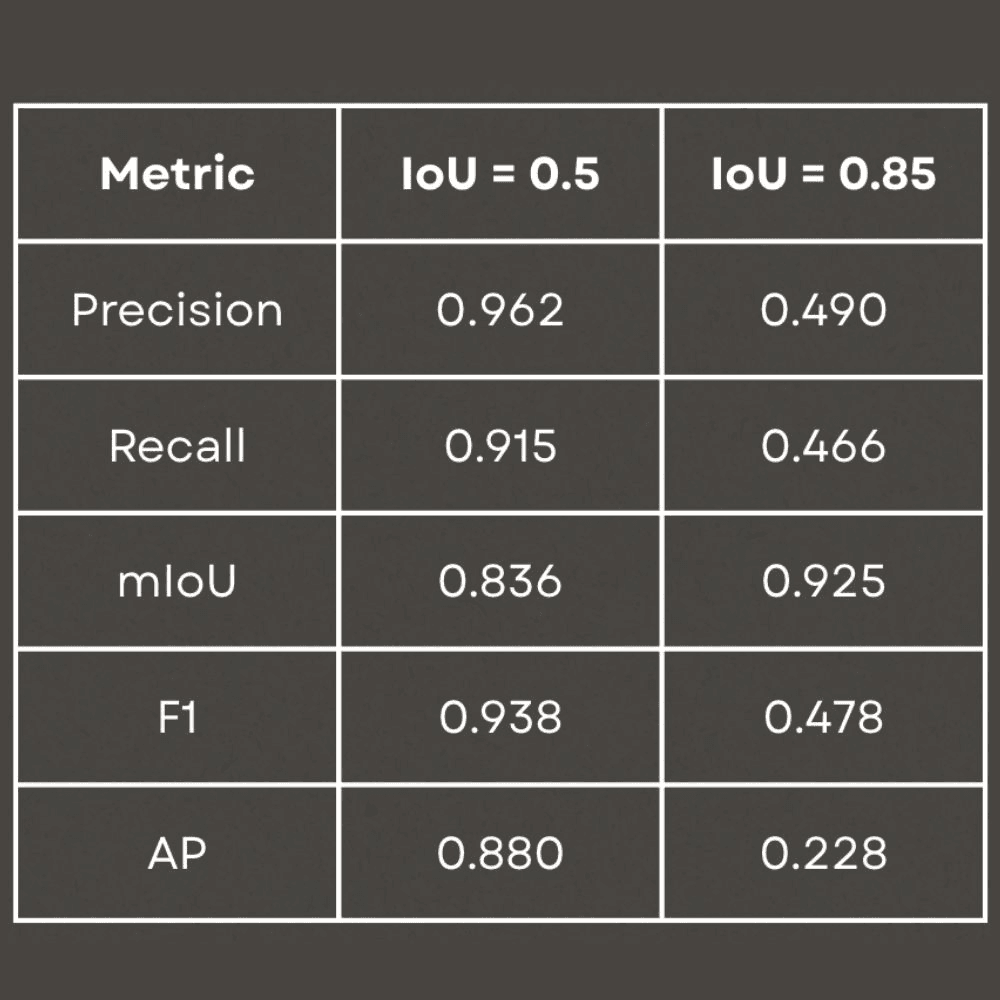
We trained the best MLHD version on a heavily varied (augmented) dataset and used early stopping so it wouldn’t just memorize the training videos. Training took about 3 hours 43 minutes on a Mac M4 Pro. Under the standard detection setting (Intersection over Union (IoU) = 0.50, meaning “reasonable overlap” between predicted and true boxes), MLHD performed strongly: Precision = 0.965 (few false alarms), Recall = 0.916 (few misses), F1 = 0.940 (overall balance), and AP = 0.884 (overall detection quality). When we required extremely tight, almost perfect box alignment (IoU = 0.85), performance dropped, which is expected and usually not necessary for real surveillance tasks that mainly need to flag that a person is present in a zone.
Overall, the takeaway is simple: a smaller model designed specifically for factory CCTV can outperform a general-purpose detector that hasn’t been adapted to the same environment.
Conclusions
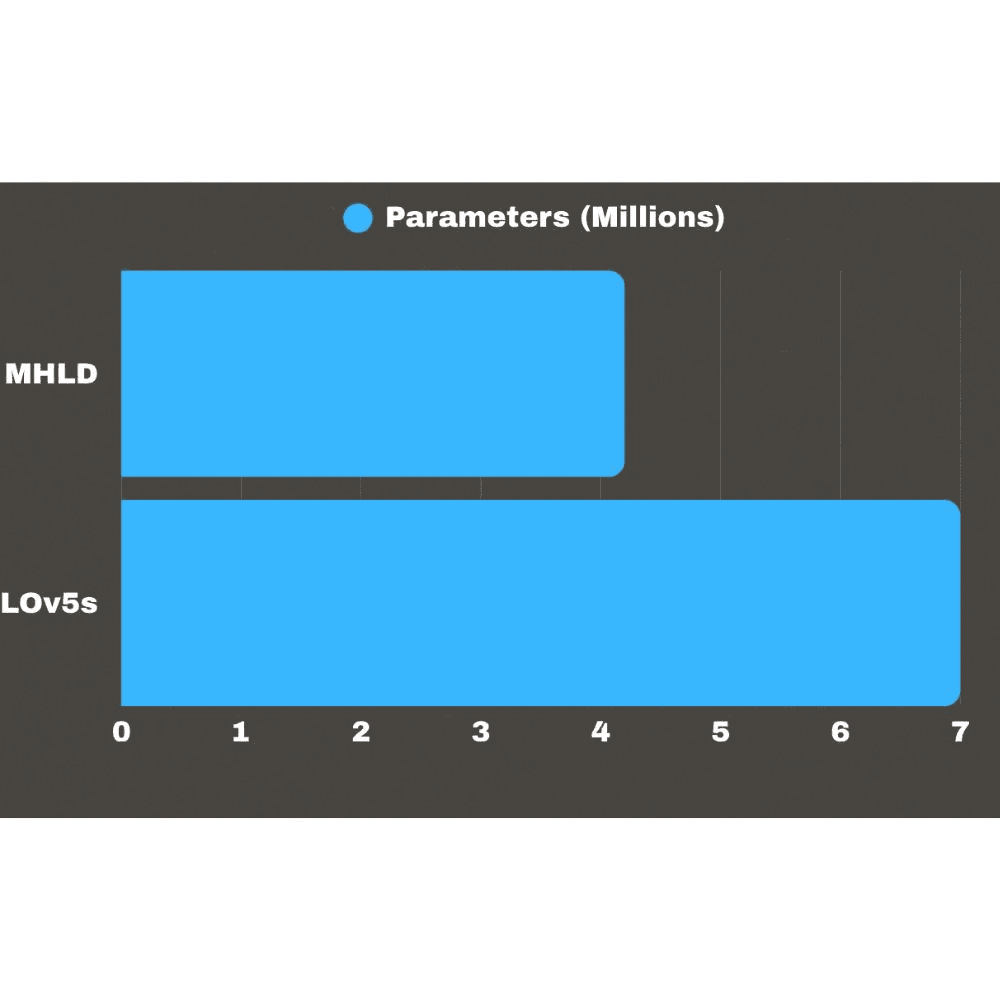
This work shows that human detection in factory CCTV can be more reliable when the model is designed specifically for industrial environments, instead of relying on large general-purpose detectors. MLHD achieves strong performance at IoU 0.50, with high precision and recall, while using fewer parameters than YOLOv5s (A state of the art detection model used as a reference point in this project). This supports the idea that domain-specific design choices can outperform pretrained models when the footage looks different from typical benchmark datasets. The drop in performance at stricter IoU thresholds reflects a deliberate tradeoff: MLHD focuses on reliably detecting that a person is present rather than drawing perfectly tight boxes. For most factory safety use cases, that tradeoff is acceptable because the main goal is dependable awareness of worker presence. As a result, MLHD can serve as a fast “first step” in a larger safety system, enabling features like restricted-zone alerts, worker–machine interaction monitoring, and near-miss prediction. Its lightweight design and low latency also make it practical to deploy across many cameras in real factory settings.
Was there a challenge during the process, and how did you manage to overcome it?
Was there a challenge during the process, and how did you manage to overcome it?
Several challenges arose during the project, most notably the model’s low accuracy in the early stages. We addressed this quickly by adjusting the target-encoding grid size and refining the loss function. Midway through development, we found recent research proposing more advanced loss formulations, so we implemented a stronger alternative to improve localization and overall stability. Training time was another major obstacle: a single run could take days, which slowed down iteration and made hyperparameter tuning much less efficient. Finally, we also struggled with presenting highly technical ideas in a way that stayed clear, engaging, and accessible. Achieving that balance required extensive rewriting and careful editing, but after multiple revisions we were able to produce an explanation that remains technically sound without sacrificing readability.
How did teamwork contribute to the success or progress of your project?
How did teamwork contribute to the success or progress of your project?
Teamwork played a huge role in the success of our project, even though collaborating wasn’t always seamless. Early on, we had to rewrite several parts of the code to make sure our training loops and inference scripts ran reliably on both Windows and Mac. We also needed to standardize variable and function names across the entire codebase. If one person used a different name for the same concept, it could break the program—and tracking down those inconsistencies sometimes took hours.
Beyond the technical work, teamwork mattered just as much in the writing. To produce a clear report, we had to communicate consistently and agree on the intent of every paragraph, so the final message didn’t feel disjointed or require major rewrites later. Overall, these challenges made coordination demanding at times, but they ultimately led to stronger, more reliable code and a more polished, coherent report.
Which key skills (soft and hard) have you acquired or strengthened during this experience?
Which key skills (soft and hard) have you acquired or strengthened during this experience?
As mentioned in the previous paragraph, learning how to work together was one of the most important skills we strengthened during this project. We also improved our ability to communicate highly technical ideas—not only through a written report, but also in a live presentation. Many of the concepts we used were fairly complex and went beyond what we had covered in class, so giving our classmates enough background to genuinely understand our approach within a 10-minute presentation was challenging. It pushed us to refine how we structure explanations, prioritize the essentials, and present results clearly and confidently.
In terms of hard skills, we gained substantial hands-on experience with convolutional neural networks (CNNs), model training, and performance tuning. We learned how to set up practical training pipelines, choose and adjust hyperparameters, and evaluate how changes affected accuracy and reliability. Just as importantly, we saw firsthand that machine learning is an applied, iterative field: theory provides the foundation, but real progress comes from experimenting, troubleshooting, and learning from failures. This project strengthened our ability to think systematically, test ideas efficiently, and make evidence-based decisions—skills that are essential for building real-world ML systems.
Do you have plans for further development or improvement of your project in the future?
Do you have plans for further development or improvement of your project in the future?
Since our project focuses on identifying people within CCTV footage, it can serve as a foundational component for broader safety systems. Accurately locating individuals in each frame creates opportunities to detect entry into restricted or dangerous zones, identify unusual behaviour patterns, and support both active and proactive monitoring solutions. A key next step in the project is the integration of a temporal component that enables tracking of individuals across consecutive frames. Rather than treating each frame independently, the system would learn temporal continuity - understanding that a person detected in one frame is likely to persist in subsequent frames. This would allow us to progressively expand the project toward more advanced safety applications tailored to specific operational needs.
From a technical perspective, an important improvement involves addressing the current limitation of one person per grid cell. At the moment, the image is divided into regions where each area can only report a single detection, which can reduce accuracy in crowded scenes. To overcome this, we would adapt the detection approach so that each region can propose multiple possible people and then apply filtering methods to keep the most reliable results. We would also refine the system to analyse the image at different levels of detail, allowing it to better distinguish individuals who are close together. These adjustments would improve robustness and scalability while keeping the overall design of the project consistent.
Did participating in this project help you better understand how your bachelor translates into real-world or applied contexts? How?
Did participating in this project help you better understand how your bachelor translates into real-world or applied contexts? How?
Participating in the MLHD project helped us clearly understand how our bachelor in Applied Mathematics translates into real-world contexts. Instead of only studying optimization, loss functions, and evaluation metrics in theory, we had to actively implement, design, and refine them to improve detection performance. Calculus became essential for understanding how the loss function changes and how the model is pushed toward better predictions through gradient-based optimization. Linear algebra showed up everywhere in the way images are represented as tensors (vectors) and in how weight updates are computed efficiently across many parameters at once (Neural Network training jargon). Probability and statistics guided how we measured performance reliably—interpreting precision and recall as real-world error rates, choosing thresholds that balance missed detections versus false alarms, and using validation/testing splits to ensure the model generalized beyond the training footage. Concepts from all areas of mathematics became practical tools rather than abstract ideas.
The project also forced us to think rigorously about model assumptions, constraints, and performance trade-offs. Designing the grid-based encoding, tuning hyperparameters, and evaluating metrics like IoU and Average Precision required precise mathematical reasoning at every step. We had to interpret quantitative results and adjust the model systematically based on empirical evidence. Overall, the experience showed us that Applied Mathematics is fundamentally about building structured, quantitative solutions to complex real-world problems.
Attach pictures
Attach pictures

References
References
[1] Alexander Buslaev, Vladimir I. Iglovikov, Eugene Khvedchenya, Alex Parinov, Mikhail
Druzhinin, and Alexandr A. Kalinin. Albumentations: Fast and flexible image augmentations, 2020.
[2] Glenn Jocher, Ayush Chaurasia, and Jing Qiu. Yolo by ultralytics. https://github.com/ultralytics/ultralytics, 2023. Version 8.
[3] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV), pages 740–755. Springer, 2014.
[4] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7.
[5] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Des-maison, Andreas Kopf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chin-tala. Pytorch: An imperative style, high-performance deep learning library, 2019. URL https://pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.ReduceLROnPlateau.html.
[6] Joseph Redmon and Ali Farhadi. Yolo9000: Better, faster, stronger, 2017.
[7] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 779–788, 2016.
[8] Bryan C. Russell, Antonio Torralba, Kevin P. Murphy, and William T. Freeman. Labelme: A database and web-based tool for image annotation. International Journal of Computer Vision, 77(1-3):157–173, 2008. doi: 10.1007/s11263-007-0090-8.
[9] Safety+Health Magazine. Workplace deaths up 12% worldwide in past two
decades. https://www.safetyandhealthmagazine.com/articles/
24808-workplace-deaths-up-12-worldwide-in-past-two-decades-report,
2024. Accessed 2025-11-30.
[10] Zhaohui Zheng, Ping Wang, Wei Liu, Li Jinze, Rongguang Ye, and Dongwei Ren. Distance-iou loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020
Link to project
Link to project
Here.