
Se nos asignó la tarea de seleccionar un conjunto de datos relevantes, aplicando algoritmos de aprendizaje automático para extraer información clave y hacer predicciones.
Resumen del proyecto
Resumen del proyecto
¿Puedes contarnos brevemente en qué consiste el proyecto que habéis desarrollado?
Analizamos un conjunto de datos sanitarios procedentes de la encuesta de 2020 de los Centros de control y prevención de enfermedades (CDC, por sus siglas en inglés) sobre salud de los pacientes. Se identificaron varios factores de riesgo, como la edad, el consumo de tabaco y el IMC. También se incluyeron indicadores binarios adicionales para añadir información sobre trastornos como los infartos, los accidentes cerebrovasculares, el asma, el cáncer de piel, la depresión, etc. Para tener una referencia de la salud del paciente, se calculó el número total de enfermedades por paciente y se utilizó esta cifra para crear un índice de gravedad: a los individuos con 5 o más enfermedades se les asignó un "1" para indicar que su estado de salud no era bueno, mientras que a los pacientes con menos de 5 enfermedades se les asignó un "0".
Nuestro objetivo era crear un modelo capaz de predecir la gravedad del estado de los pacientes en función de factores de riesgo como el sexo, la edad, el consumo de tabaco o de alcohol, la salud general, la diabetes y el IMC. Utilizamos árboles de decisión, regresión logística y redes neuronales multicapa para comparar y contrastar la capacidad del modelo para predecir con precisión la gravedad de los pacientes.
Detalles técnicos
Detalles técnicos
¿Puedes explicar los aspectos técnicos del proyecto? ¿Qué software o qué herramientas utilizas?
Utilizamos Python en todo el proyecto. Utilizamos la biblioteca Pandas para la limpieza de datos y Scikit-Learn para la implementación de algoritmos de aprendizaje automático.
Desafíos y soluciones
Desafíos y soluciones
¿Hubo algún desafío importante durante el proyecto? ¿Cómo se superó? ¿Hay algún momento que destaques especialmente en cuanto a resolución de problemas?
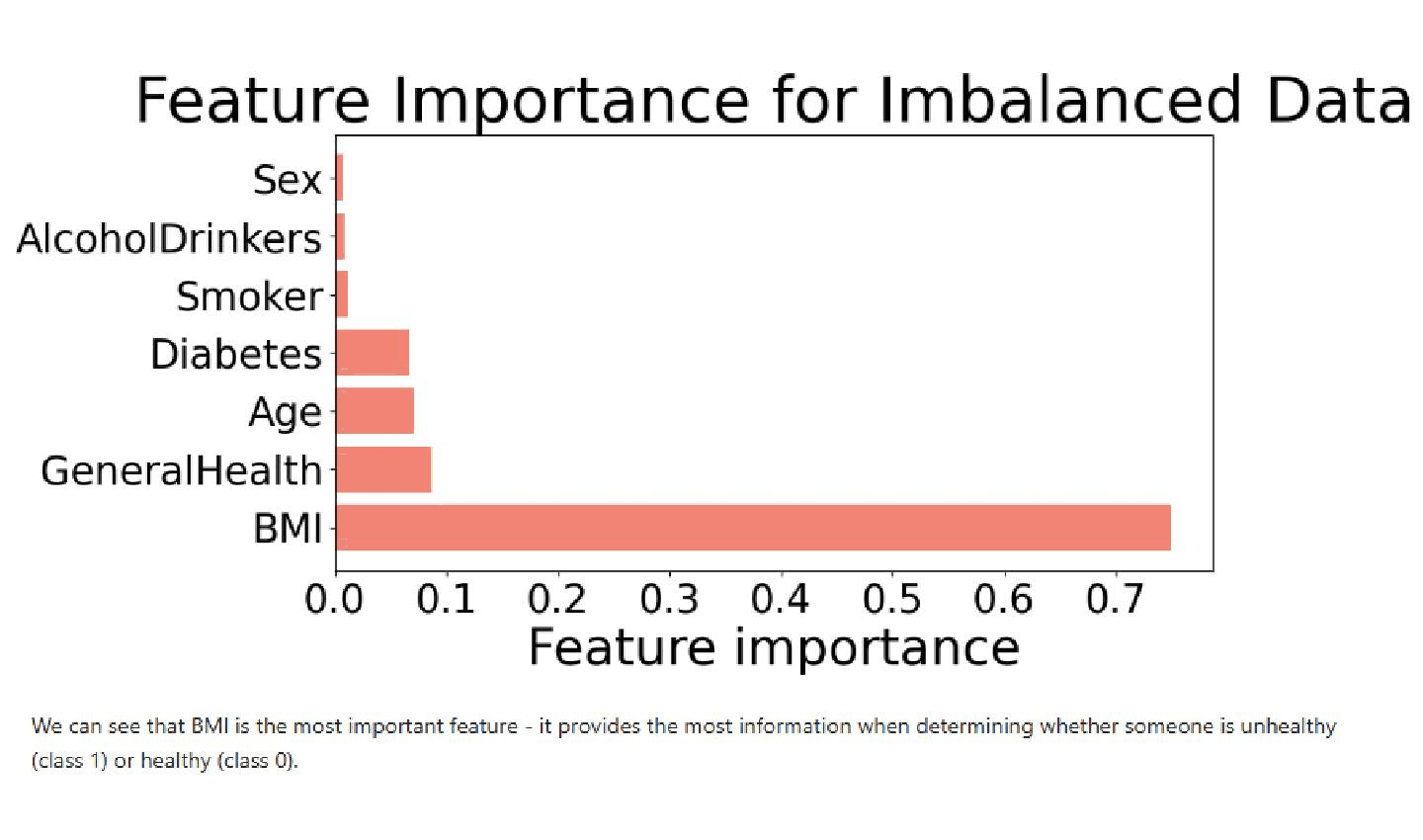
El desafío más importante fue el desequilibrio entre las categorías de personas sanas y personas no sanas. Teníamos 231 023 muestras de individuos sanos y solo 6607 de los que no lo estaban. Era un problema complejo, porque corríamos el riesgo de que el modelo creara sesgos para hacer predicciones sobre los individuos de la categoría mayoritaria con el objetivo de minimizar los errores de predicción. Para resolver el problema, empezamos por ejecutar los algoritmos en el conjunto de datos desequilibrado, con el fin de probar el rendimiento del modelo. Después, redujimos las muestras de la categoría mayoritaria hasta quedarnos únicamente con 6607, el mismo número que en la categoría no mayoritaria.
Otro de los retos fue encontrar una métrica de evaluación adecuada para los modelos. Los árboles de decisión, la regresión logística y las redes neuronales multicapa se entrenan para minimizar los errores de predicción. Sin embargo, debido a la gran cantidad de datos con los que trabajábamos y la variedad de las funciones, era muy difícil crear un modelo que clasificara correctamente a todos los pacientes. Además, nuestro objetivo principal no era crear un algoritmo que clasificara correctamente a cada individuo en la categoría de salud correspondiente. Lo que queríamos era maximizar el número de pacientes clasificados correctamente como positivos reales, es decir, como personas no sanas. En el campo de la atención sanitaria, es más seguro actuar con precaución, por lo que es preferible decirle a un paciente sano que no lo está que cometer el error contrario con los pacientes que sí tienen problemas de salud, ya que esto puede hacer que dichos problemas se ignoren y crear problemas más graves. Acabamos centrándonos en maximizar la capacidad de recuperación o recall de estos algoritmos, una métrica que se extrae observando las matrices de confusión de los modelos.
Colaboración y trabajo en equipo
Colaboración y trabajo en equipo
¿Colaborasteis con otros estudiantes o miembros del equipo en este proyecto? ¿Cómo contribuyó el trabajo en equipo al éxito o progreso del proyecto?
En las primeras etapas del proyecto, fue útil intercambiar ideas entre nosotros, especialmente cuando estábamos intentando averiguar cómo trabajar con un conjunto de datos tan grande, que requería una limpieza exhaustiva. También nos fue de gran ayuda discutir sobre cómo crear una variable predictiva sólida que proporcionara resultados interesantes, originales y relevantes.
Aprendizaje y conclusiones
Aprendizaje y conclusiones
¿Qué lecciones o habilidades clave habéis obtenido al trabajar en este proyecto?
Fue muy interesante ver el proceso de entrenamiento de un algoritmo a partir de un conjunto de datos sin procesar. En clase, habíamos estudiado las expresiones matemáticas de los algoritmos y su funcionamiento, pero el proyecto nos permitió llevar este conocimiento a la práctica y crear modelos con aplicaciones en el mundo real.
Desafíos y Soluciones
Referencias
Referencias
Enlace al repositorio de Github donde se almacena el código del proyecto.