- Home
- News And Events
- News
- A New Framework For Data Policy
A New Framework for Data Policy

In the 9th paper of Digital Revolution and New Social Contract research program, Andrea Renda argues that policymakers should regulate data flows analyzing the evolution of data’s value as a function of its diffusion.
Analysts have long struggled to incorporate data into their conceptual frameworks due to the chameleonic features of information, which often clash with otherwise well-established tenets in economic theory. In this first paper on the future data economy, Andrea Renda (CEPS) dives into the unique characteristics that make data unlike any other product or service, in order to help policymakers understand their different types, optimize their flow, and ultimately enhance prosperity. The elusive economics of data escape easy classifications and turn the design of appropriate policies to govern its efficient flow into a difficult task, but we must think critically about this crucial domain and urge leaders to stand up to the challenge.
What do we know about data? One of its most important characteristics is that data can be easily decomposed, rebuilt, and repackaged, which means that a single piece of data can often lead to endless possibilities for generating valuable insights. Another way to think of this is that data is multi-purpose and multi-status, or that the same data asset can show a different face and value depending on when it is observed, how it is observed, and who is observing. In turn, these features make determining the value of data and regulating its efficient flow extremely difficult, as these exercises often boil down to contingent analyses based on each individual’s willingness to pay.
However, we can approximate the challenge of optimising data flows by considering data’s utility functions, which analyse the evolution of its value in terms of its diffusion.
Contrary to the common belief that data is always worth more when viewed and accessed by everyone, not all data reaches the peak of its value when openly accessed and shared. Some types of data (Type A), such as a bus timetable, do feature public good characteristics and see their value maximized along their diffusion. Other types of data (Type B), for example medical research that requires validation and authentication, reach a peak of their value when shared within a contained group. And yet other types of data (Type C), including data used in the context of business, such as sales reports, are worth more when kept somewhat private (See Figure 1).
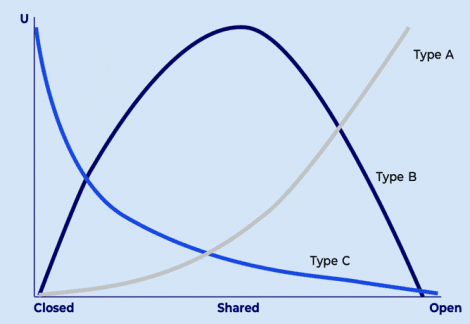
Figure 1: The utility functions of data
An optimally calibrated data policy should thus ensure that Type A data gets shared as much as possible; Type B is shared to the extent that it maximizes its value (the actual peak may vary); and Type C data is kept mostly private. In an ideal world, the best mechanism for optimizing these diffusion levels would be the market, but because the economics of data is fraught with idiosyncrasies that reduce its overall societal value, there is room for improving our data governance strategies and optimising data flows, by removing some of the distortions, asymmetries, and power concentration effects that exist today.
Against this backdrop, the author presents a decalogue for policymakers to restrict, encourage, and mandate different types of data flows and thus ensure they lead to an efficient regime. These include: minimizing the flow of personally identifiable data; encouraging businesses to share data (altruism); enabling managed data-sharing within data spaces; avoiding data hoarding and value capture; facilitating switching between cloud and edge services; obliging businesses to share data “for good” and to tackle emergencies; ensuring fair contractual conditions in data-sharing contracts, increasing data sovereignty; creating trusted and independent data intermediaries; and promoting data stewardship and literacy.
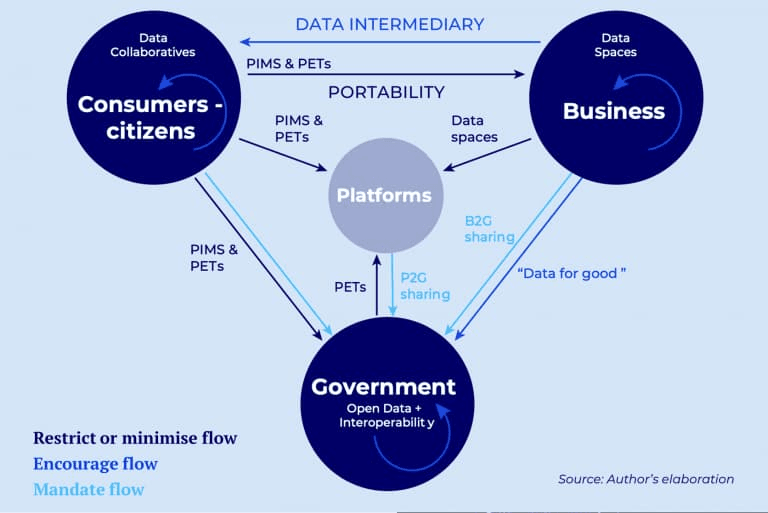
Figure 2: Optimal data flows
Figure 2 summarizes these policy recommendations with a visual representation of the types of data that policymakers should aim to restrict; data flows that ought to be encouraged; and data flows that might need to be mandated as they would not otherwise occur. It also shows some of the key technologies and governance arrangements that will probably be crucial to deliver the expected results, including personal information management systems (PIMS) and privacy- enhancing technologies (PETs); data collaboratives (especially among citizens); data spaces for businesses; and interoperability arrangements across and between governments.
The paper should stimulate reflection and invite the reader to think critically about this extremely crucial domain. We must urge policymakers to create the governance arrangements and the policy preconditions that will lead to optimal data flows and enhanced prosperity.
Andrea Renda is Senior Research Fellow and Head of the CEPS Unit on Global Governance, Regulation, Innovation and the Digital Economy (GRID).
To read more about the topic and download the full paper, click here.