
The development of large language models (LLMs) has its roots in the study of the nervous system. Santiago Ramón y Cajal, a pioneering neuroscientist, laid the foundation by positing that the nervous system consists of discrete individual cells. This concept, for which he received the Nobel Prize, has evolved over time, leading to the creation of artificial neural networks (ANNs) and deep learning algorithms that mimic the structure and function of the human brain.
In 1958, psychologist Frank Rosenblatt invented the perceptron, a rudimentary form of artificial neural network. This invention marked the beginning of the development of “artificial brains.” ANNs consist of neurons connected in layers, each performing specific mathematical functions. The first convolutional neural network was introduced in 1988, paving the way for more complex architectures.
Deep learning emerged as a specialized subfield of machine learning, focusing on algorithms inspired by the brain’s structure and function. These algorithms automatically learn to represent data through multiple layers of interconnected nodes, or “neurons.” Deep learning has proven to be particularly effective in handling large and complex data sets, leading to breakthroughs in image recognition, natural language processing, and autonomous vehicles. One of the most notable applications of deep learning was developed by DeepMind, a London-based startup now part of Google. They created models that could learn to play video games in a manner similar to humans.
The model for the modern transformer was proposed in the 2017 paper titled “Attention Is All You Need” by Ashish Vaswani and colleagues from the Google Brain team. This architecture revolutionized the field by introducing a simplified yet powerful structure that excels in various applications. Language models like GPT-4 rely on input and output embeddings to interpret and generate text. These embeddings act as a mathematical dictionary, positioning semantically similar words close to each other in a mathematical space. Traditional machine learning models struggled with understanding word order, a critical aspect of sentence meaning. The introduction of positional encoding, combined with input embeddings, allows transformer models to understand sentence structure better and generate meaningful output.
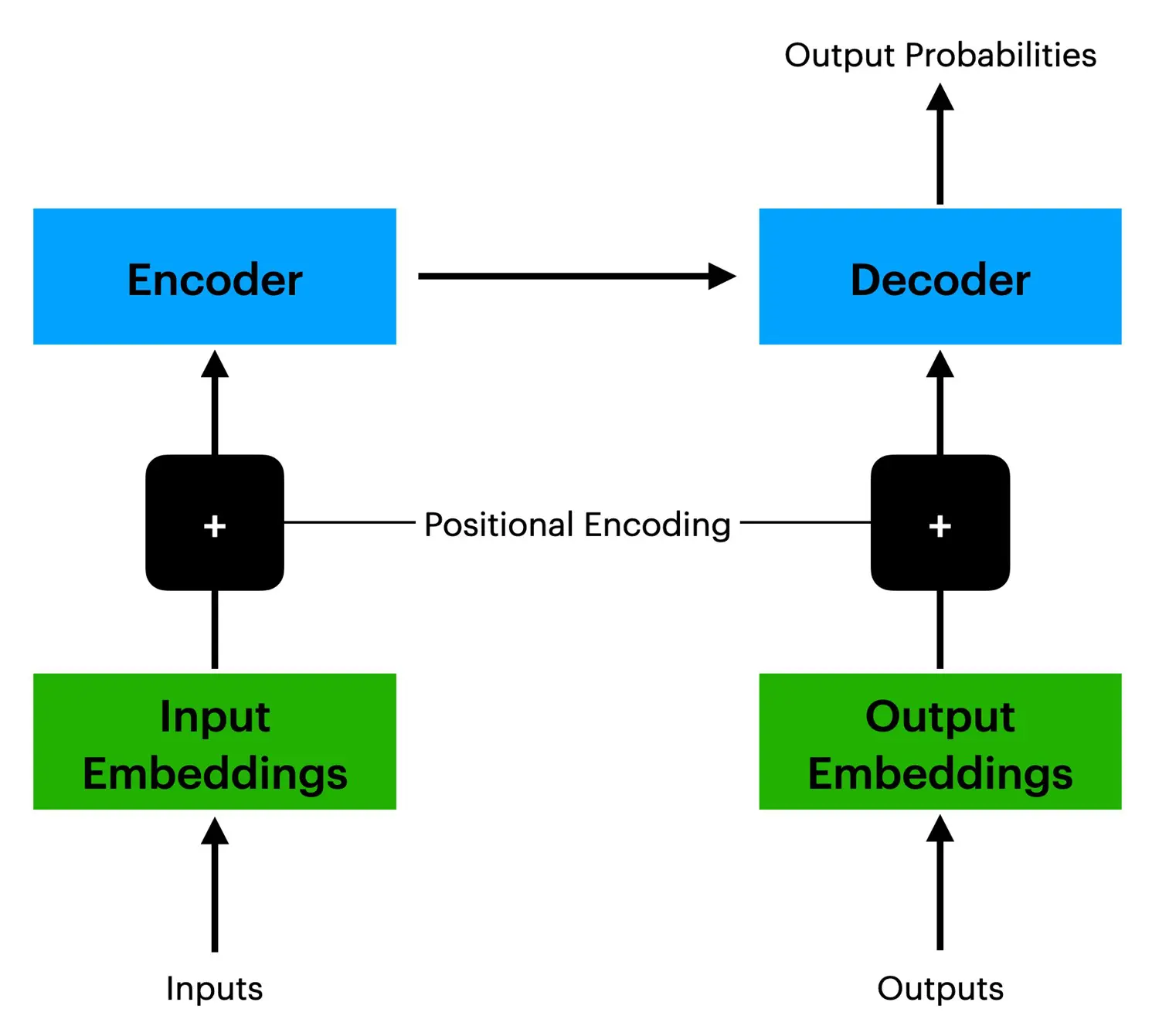
Source: Author
GPT models are trained on vast text data, including sources like Common Crawl, BooksCorpus, and Wikipedia. GPT-4, with its 175 billion parameters, benefits immensely from this extensive training data. Efforts are also underway to improve the model’s capabilities in non-English languages.
The journey of LLMs from their origins in neuroscience to their current state-of-the-art architectures is a testament to the rapid advancements in the field. These models have revolutionized natural language processing and shown promise in various other domains, making them a cornerstone of modern artificial intelligence.
LLMs have evolved to serve as communication layers within AI systems. They can interpret and explain results from more specialized and accurate AI models, such as search engines. The rise of LLMs has significantly impacted traditional information sources, including search engines like Google and Bing. One of the challenges arising from this development is the generation of AI-created fake responses, or hallucinations, which calls into question the trustworthiness of information. To address these issues, fine-tuning LLMs has become imperative. This allows for higher-quality results and the ability to train on a broader set of examples. The process involves preparing and uploading training data, training a new fine-tuned model, and then deploying that model for specific tasks.
Furthermore, the use of embeddings in LLMs has expanded their capabilities with a range of functionalities, including search, clustering, recommendations, anomaly detection, and classification. These advancements contribute to making LLMs more versatile and effective, but they also underscore the need for establishing trust and reliability in AI-generated information.
OpenAI is not the sole entity in the market. Specialized models like Ajax GPT are already integrated into iPhones for text prediction, and it’s anticipated that full LLMs will soon run locally without the need for cloud computing. Many users are interacting with these technologies without even realizing it.
In addition to OpenAI, Google has its own LLM called Bard, which is integrated with the world’s most reliable search engine and supports coding tasks. Google has been in the AI development space since the launch of its search engine in 1997. Meta, formerly known as Facebook, has also entered the market with a freely downloadable LLM named Llama. Although it is not open source as claimed, it allows users to easily download and create a local LLM without requiring an API. This has led to the development of specialized variants, including coding-focused LLMs.
LLMs In Education
Education is among those sectors undergoing significant changes thanks to the introduction of LLMs. These tools offer immense potential for aiding technical researchers and professionals, but there is the concern that they could also be used for cheating, which means students miss out on acquiring fundamental skills. For example, programming students benefit from LLMs, offering functionalities – though not yet perfect – like code generation, testing, and documentation.
Beyond coding, LLMs have a wide range of applications for learners. They can assist in brainstorming by generating lists of related words and concepts, help in project planning by outlining objectives and requirements, and contribute to character development and dialogue writing. They can also be instrumental in research, acting as advanced search engines by generating lists of relevant articles, books, and websites (when integrated with a search engine). Furthermore, they have potential in educational settings, offering practical exercises and challenges for revision and possibly tutoring in the future.
For teachers, LLMs are becoming increasingly useful in class preparation and lesson planning. and can assist professors in various ways, such as querying documents in PDF form through specific websites and plugins like ChatPDF. LLMs can also generate quizzes and practice exercises for students (though at this point it is still quite necessary to verify that these exercises are sensible and relevant to the content.)
Using LLMs in exams should vary depending on the skills being tested. For exams focusing on fundamental skills or in situations where external materials are not allowed, they should not be used as aids. On the other hand, the use of all available LLM tools should be considered in group projects because of how they help test the ability to achieve larger results. As always, it’s important to explicitly reference when LLMs are used, in order to maintain academic integrity.
Students may unknowingly use LLMs on a regular basis — for example through tools like Grammarly and Quillbot. While these tools are acceptable for correcting writing, using them to generate text is considered the same as using any other LLM and could be categorized as academic dishonesty. This is a line that can be difficult for students to understand, if at least at first, and so it is the role of the professor and academic institution to educate students and ensure they understand how to use such tools correctly.
Because the truth is that misusing LLMs in academic settings can lead to serious consequences. Plagiarism can severely damage a student’s academic reputation and lead to disciplinary actions such as a failing grade, suspension, or expulsion.
Nevertheless, the good outweighs the bad and while LLMs are still under development, they have the potential to revolutionize education and other various fields by automating repetitive tasks, improving code quality, and facilitating communication. They are a valuable tool for enhancing productivity and are essential for a student’s future career.
Indeed, the journey of LLMs from their roots in neuroscience to sophisticated AI architectures is remarkable. They serve as vital communication layers in various AI systems but pose challenges, such as generating untrustworthy information. Fine-tuning and embeddings have expanded their capabilities, but there is a need for trust, reliability, and data security. Multiple companies offer specialized LLMs, making the market diverse. In education – and essentially all industries – LLMs can be both a boon and a bane. It is up to us to decide how to use and develop them.
© IE Insights.







