
This is an AI-powered book recommendation system that analyses the emotional and thematic trends of a book to suggest others that match the reader’s desired emotional experience. It uses NLP, sentiment analysis, and clustering techniques to extract a book’s emotional trajectory, the emotional profiles of the main characters and the main themes, later using this data to make recommendations. The project started as a research paper and later we developed a full-stack web application, making the solution interactive and accessible to end users.
Project Overview
Project Overview
Can you provide a brief overview of the project you've been working on?
We started by researching the best and current approaches for analysing emotions in books, aiming to use them for emotionally driven book recommendations. From our literature review, we observed that the current solutions were mostly focused on metadata and user reviews, overlooking in-text emotional analysis.
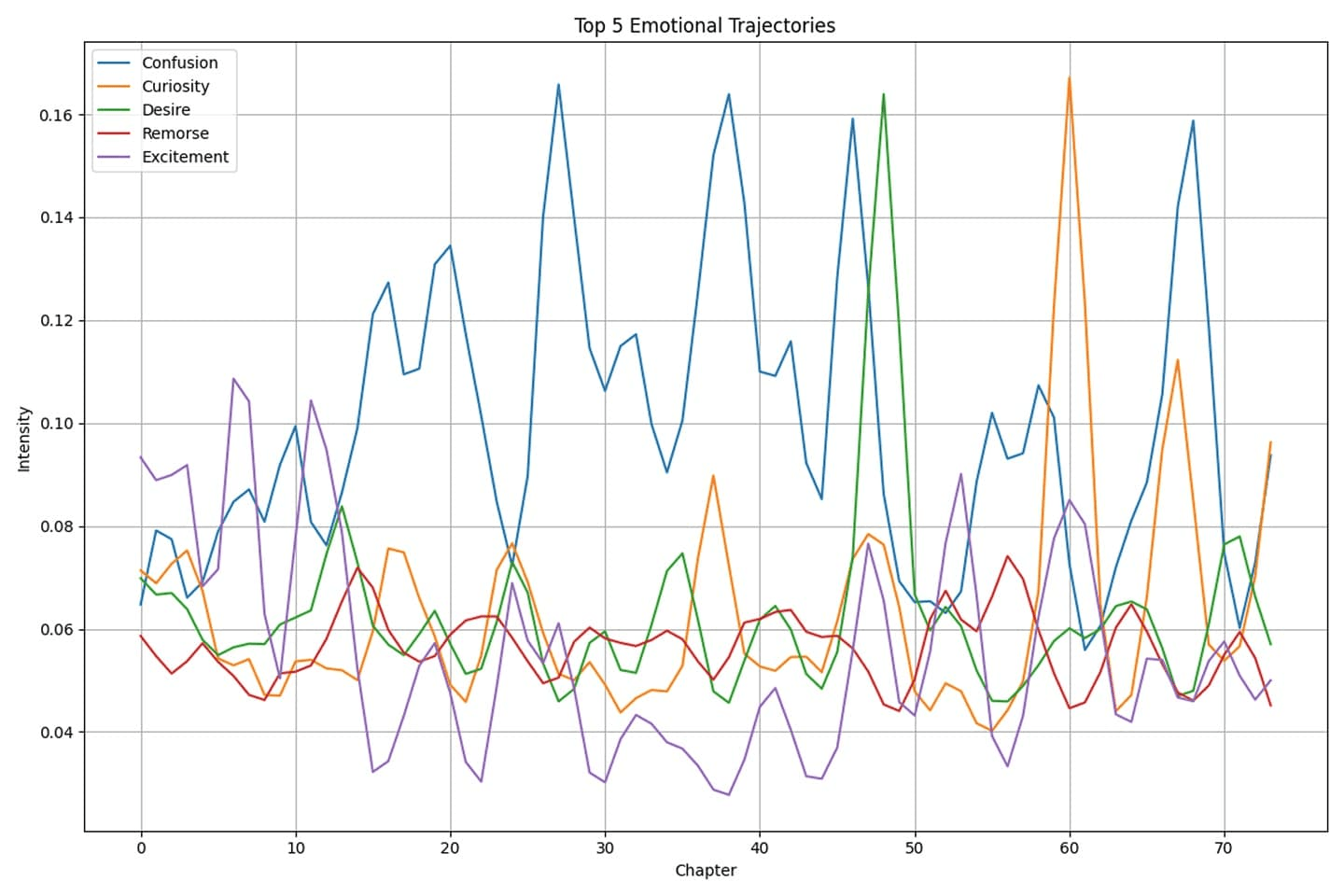
To address the limitations of existing book recommendation systems, we built a solution that analyzes the emotional and thematic content of books. Our system uses a fine-tuned DistilBERT model to detect 28 nuanced emotions across the text, and TextBlob to compute sentiment polarity for each chapter. These emotion and sentiment patterns are smoothed using Gaussian filters to highlight the overall narrative arc. We also analyze the main characters' emotions by detecting frequently mentioned names and evaluating the surrounding emotional context. The book's topics are extracted through TF-IDF vectorization and Latent Dirichlet Allocation (LDA) and visualized in a chapter-topic heatmap. These features together form a book's emotional profile, which is then used to generate recommendations based on emotional similarity, shared dominant feelings, or clustering patterns.
Users can analyze uploaded .txt files via our web app. The "Scan" feature visualizes sentiment and emotion plots, while the "Recommend" feature generates emotionally aligned book suggestions using cosine similarity, dominant emotion matching, or KMeans clustering.
Purpose of the project
Purpose of the project
What inspired or motivated you to choose this particular project?
We were inspired by the idea that nowadays, when you look for a book, you only get recommendations based on genre or reader similarity, but we think that books are more than genres, and readers often seek stories that will evoke a specific feeling (for example, hoping to recreate the emotional experience of a book they loved), which is difficult to find using traditional systems. Books are emotional journeys, and we get attached to how they make us feel. We wanted to help readers discover stories based on how they want to feel, using NLP and machine learning to build a more human centric system.
Technical Details
Technical Details
Could you explain the technical aspects of your project? What software, tools do you use?
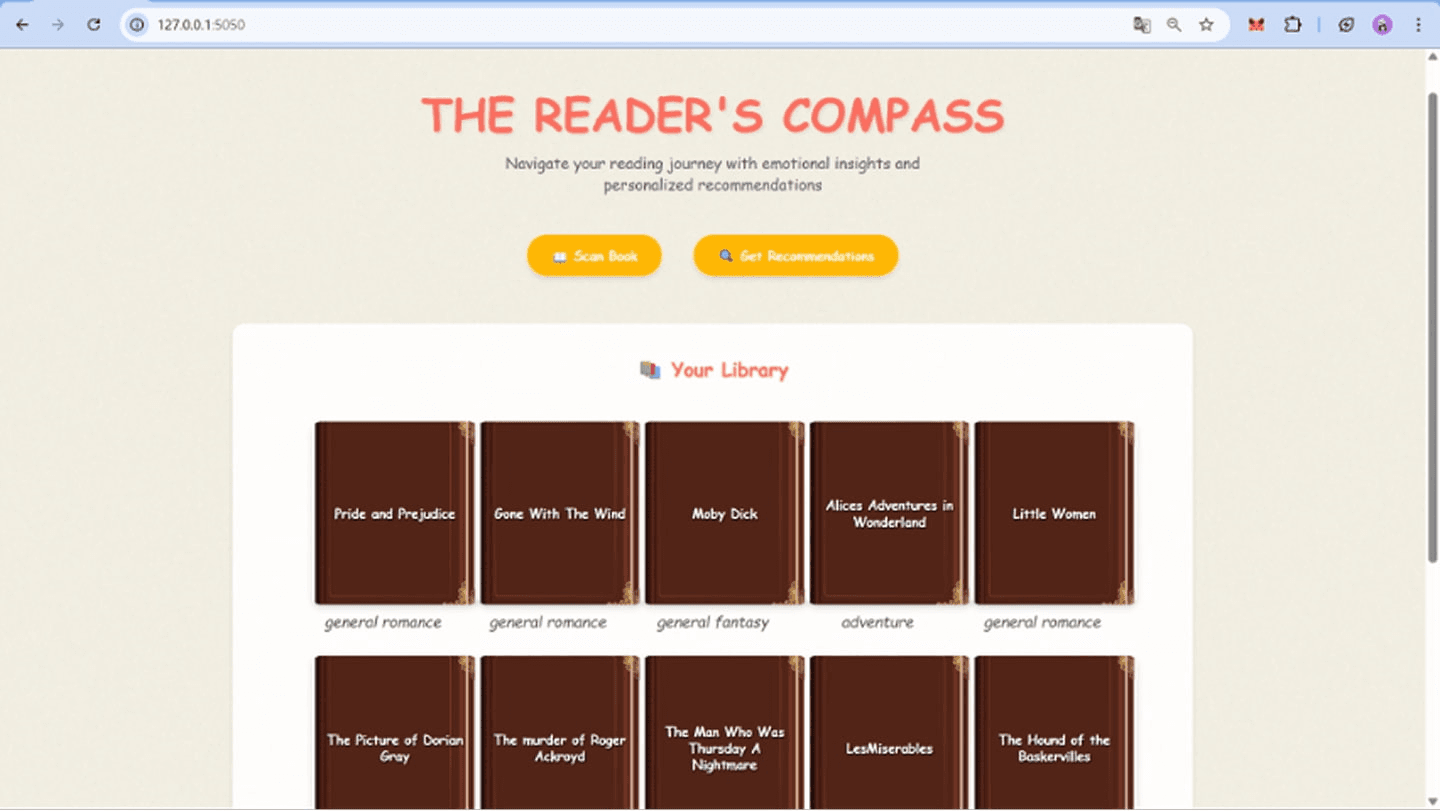
- We used Hugging Face Transformers to access a pre-trained DistilBERT model fine-tuned on the GoEmotions dataset, which enabled us to map book content to 28 distinct emotions (e.g. admiration, joy, fear, sadness, etc.).
- TextBlob was used for sentence-level polarity, TF-IDF and LDA for topic modeling, and SpaCy NER for character emotion profiling.
- The backend was built with Flask and the frontend with HTML/CSS/JS.
- For recommendations, we implemented a hybrid system combining cosine similarity, dominant emotion matching, and KMeans clustering.
- The system processes .TXT files and outputs visual plots and recommendation results.
Challenges and Solutions
Challenges and Solutions
Were there any significant challenges you encountered during the project, and how did you overcome them? Can you share a specific problem-solving moment that stands out in your project?
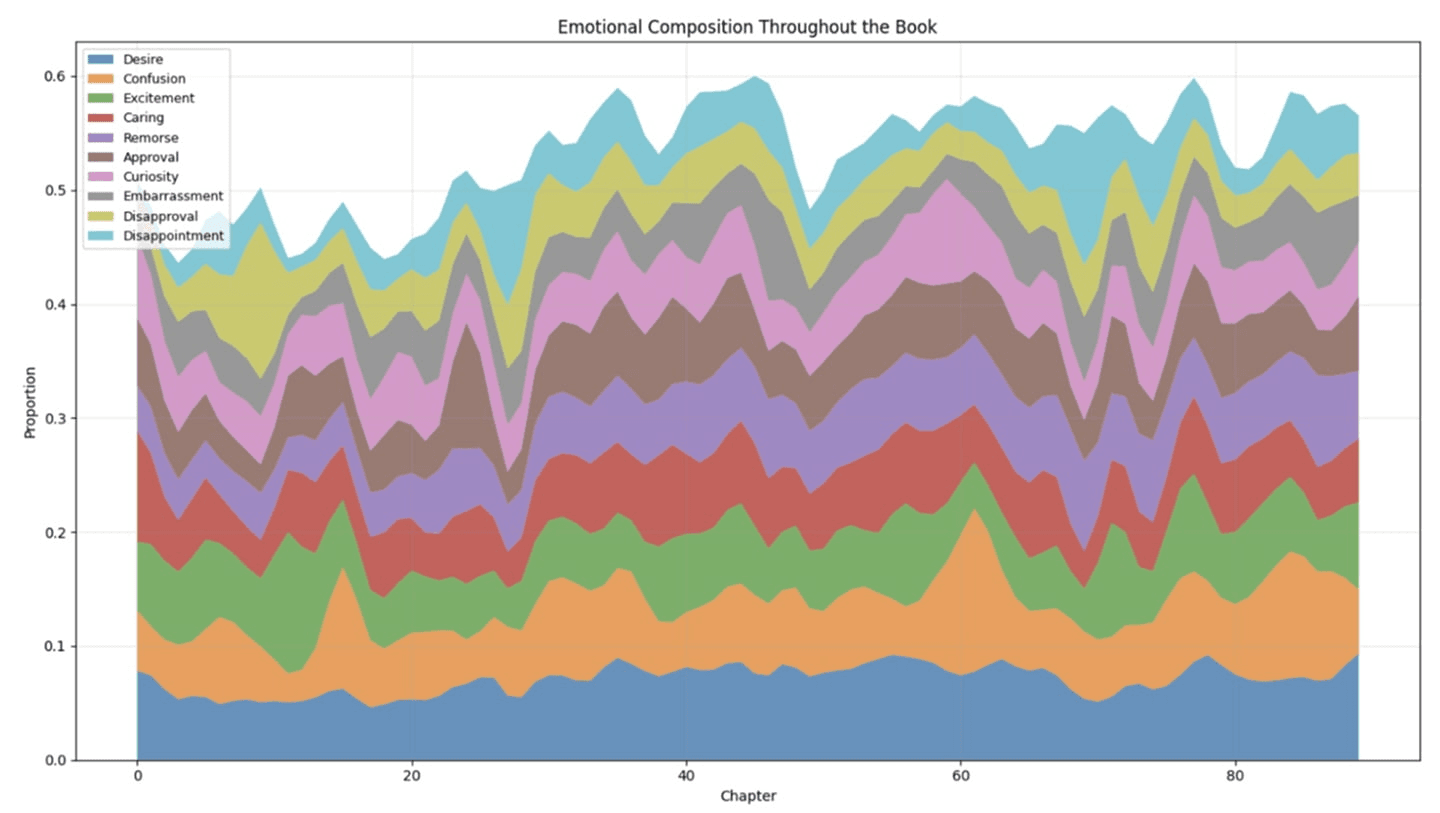
One major challenge I faced was adapting different methods to handle long texts and extract useful and accurate emotional trends across chapters. I solved this by combining transformer-based models with smoothing techniques and batching inputs to optimize memory and speed.
Another challenge was to track the emotions felt by the different main characters, where I had to use fuzzy matching, NER and context windowing to unify the different variations of the same character name.
Additionally, managing the time it took the BERT model to give results on large books was also challenging; we addressed this by batching sentences and caching models and tokenizers.
Collaboration and Teamwork
Collaboration and Teamwork
Did you collaborate with other students or team members on this project? How did teamwork contribute to the success or progress of your project?
Yes, this was a group project developed in collaboration with Laura Cuellar, Ismael Picazo and Sebastian Perilla. Working together allowed us to efficiently tackle the different modules: modeling, front-end, back-end, and evaluation. We produced a publishable article and a nearly production-ready website by combining our coding and design skills into a unified system that balances scientific depth with usability. Our complementary strengths enabled fast model responses, insightful visualizations, and a rigorous evaluation of the solution’s effectiveness.
Learning and Takeaways
Learning and Takeaways
What key lessons or skills have you gained from working on this project?
I gained extensive knowledge on how to apply numerous NLP techniques and integrate them with transformer models and hybrid recommendation systems. I also learned how to bridge the gap between academic research and user-facing applications, and the importance of user experience in deploying AI tools effectively.
Future Development
Future Development
Do you have plans for further development or improvement of your project in the future?
The website can be currently accessed on GitHub, but we plan to deploy it publicly, making it accessible to real-world users.
We aim to refine emotional inference, adopt more advanced modeling techniques, and expand the book database which is currently limited to Project Gutenberg texts.
We also plan to test the system with real users and benchmark its performance on larger, more diverse datasets.
additional information
additional information
Do you have plans for further development or improvement of your project in the future?
This project was part of the final project for the BCSAI course of “AI: Natural Language Processing and Semantic Analysis”.
The link to the public repository of the project.