
We were given the task of selecting an interesting and relevant dataset, applying machine learning algorithms to extract relevant information about the data and make predictions.
Project Overview
Project Overview
Can you provide a brief overview of the project you’ve been working on?
We analyzed a healthcare dataset from the 2020 CDC annual survey, centered on patient health. Various risk factors, such as age, smoker status, and BMI, were listed. There were additional binary indicators for medical conditions such as heart attack, stroke, asthma, skin cancer, depressive disorder, etc. To create a measure for patient health, we computed the total number of diseases per patient, from which we created a binary health severity score: individuals with 5 or more medical conditions were assigned a "1", indicating they were unhealthy, and patients with less than 5 medical conditions were assigned a "0".
Our goal was developing a model capable of predicting patient health severity scores based on key risk factors, namely sex, age category, smoker status, alcohol drinker, general health, diabetes, and BMI. We made use of decision trees, logistic regression, and multi-layer neural networks to compare and contrast their ability to accurately predict the severity score.
Technical Details
Technical Details
Could you explain the technical aspects of your project? What software, tools do you use?
We utilized Python throughout the entire project. We used the Pandas library for data cleaning, and Scikit-Learn for the implementation of machine learning algorithms.
Challenges and Solutions
Challenges and Solutions
Were there any significant challenges you encountered during the project, and how did you overcome them? Can you share a specific problem-solving moment that stands out in your project?
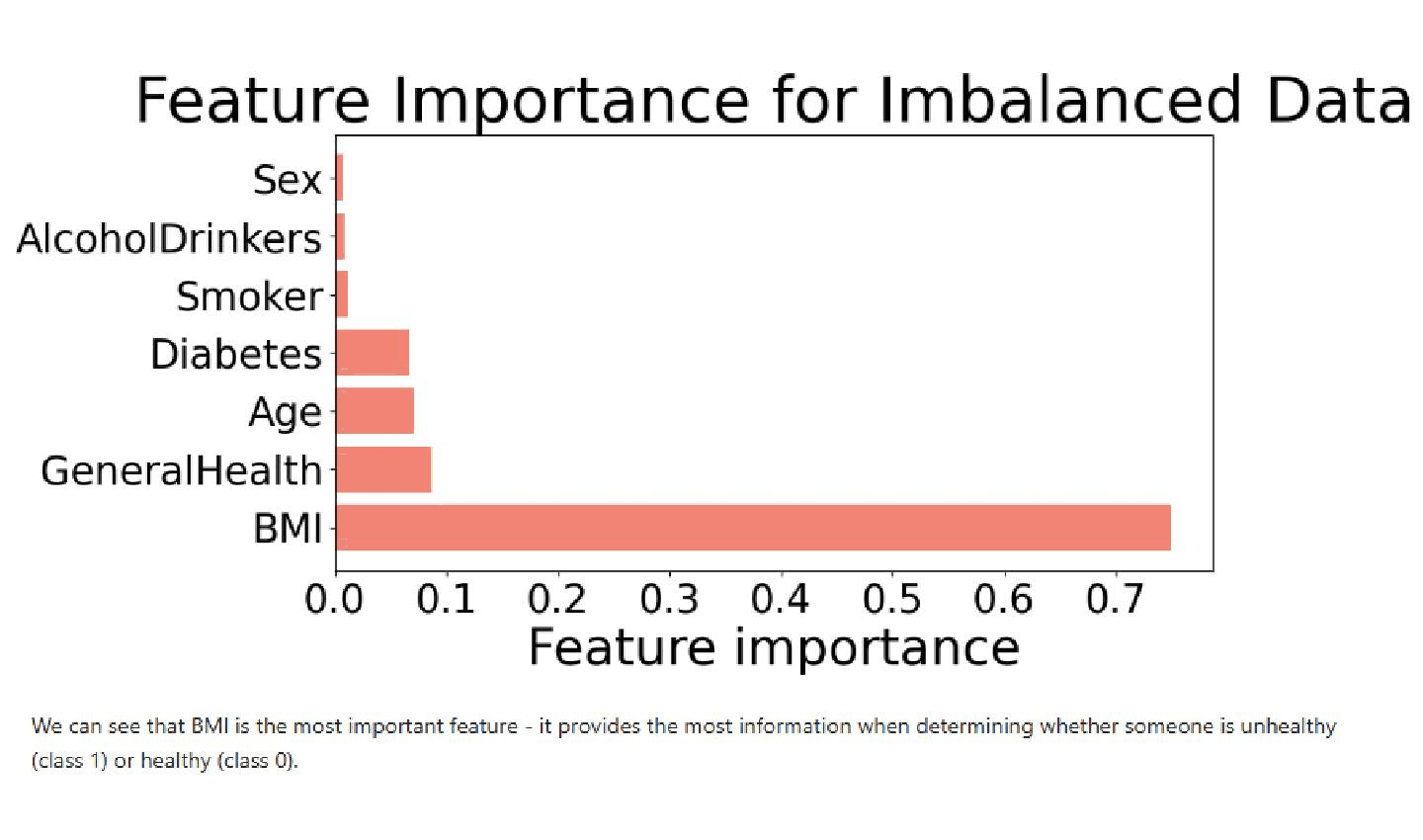
The most prominent challenge throughout the project was the imbalance in the "healthy" and "unhealthy" classes. We had 231,023 samples of healthy individuals, and only 6607 samples of unhealthy individuals. This was an issue because we risked the model becoming biased to predicting individuals from the majority class in order to minimize prediction error. To combat this problem, we firstly ran all algorithms on the imbalance data as a baseline test for model performance, and then undersampled the majority class in order to have 6607 samples from each class in a balanced dataset.
We also faced the challenge of finding an appropriate evaluation metric for the models. Decision trees, logistic regression, and multi-layer neural networks are trained in order to minimize the prediction error; nonetheless, because of the large amounts of data we had and the variety in the features, it was very difficult to create a model that would correctly classify all patients. Moreover, our main focus was not creating an algorithm that would correctly classify every single individual in their respective health class. We wanted to maximise the number of unhealthy patients that were correctly classified as unhealthy, known as true positives. In the context of healthcare, it is safer to err on the side of caution and incorrectly tell a healthy patient they are unhealthy, rather than tell an unhealthy patient they are healthy - potentially leading them to neglect their deteriorating health. We ended up focusing on maximizing recall of these algorithms, a metric which is extracted by looking at the confusion matrices of the models.
Collaboration and Teamwork
Collaboration and Teamwork
Did you collaborate with other students or team members on this project? How did teamwork contribute to the success or progress of your project?
In the early stages of the project, it was useful to bounce ideas off of each other, especially when figuring out how to tackle the very large dataset that required extensive cleaning, and when discussing ideas on how to create a strong predictor variable that would provide interesting, original, and relevant results.
Learning and Takeaways
Learning and Takeaways
What key lessons or skills have you gained from working on this project?
It was interesting to see the process of training an algorithm starting from a raw dataset. In class, we had seen a lot of the mathematics behind all of the algorithms and gained a deep understanding of why they work the way that they do; this project allowed us to take that knowledge and see it in action, creating models that had practical applications in the real world.
Challenges and Solutions
References
References
Link to the Github repository where the code of the project is stored.